Web Scraping vs Web Change Detection: What Developers Need to Know
Most projects that end up over-engineered started with the wrong framing. A developer decides they need to "monitor a price" and builds a full scraping pipeline with a scheduler, a database, a diff engine, and a Slack bot. Three months later, they're maintaining 400 lines of glue code that breaks every time the retailer renames a CSS class.
The opposite mistake is just as common: someone uses a change detection tool to pull a structured dataset for analytics and wonders why they're getting noisy, inconsistent alerts instead of clean records.
These are different jobs. They call for different tools. Here is how to tell them apart.
What Is Web Scraping?
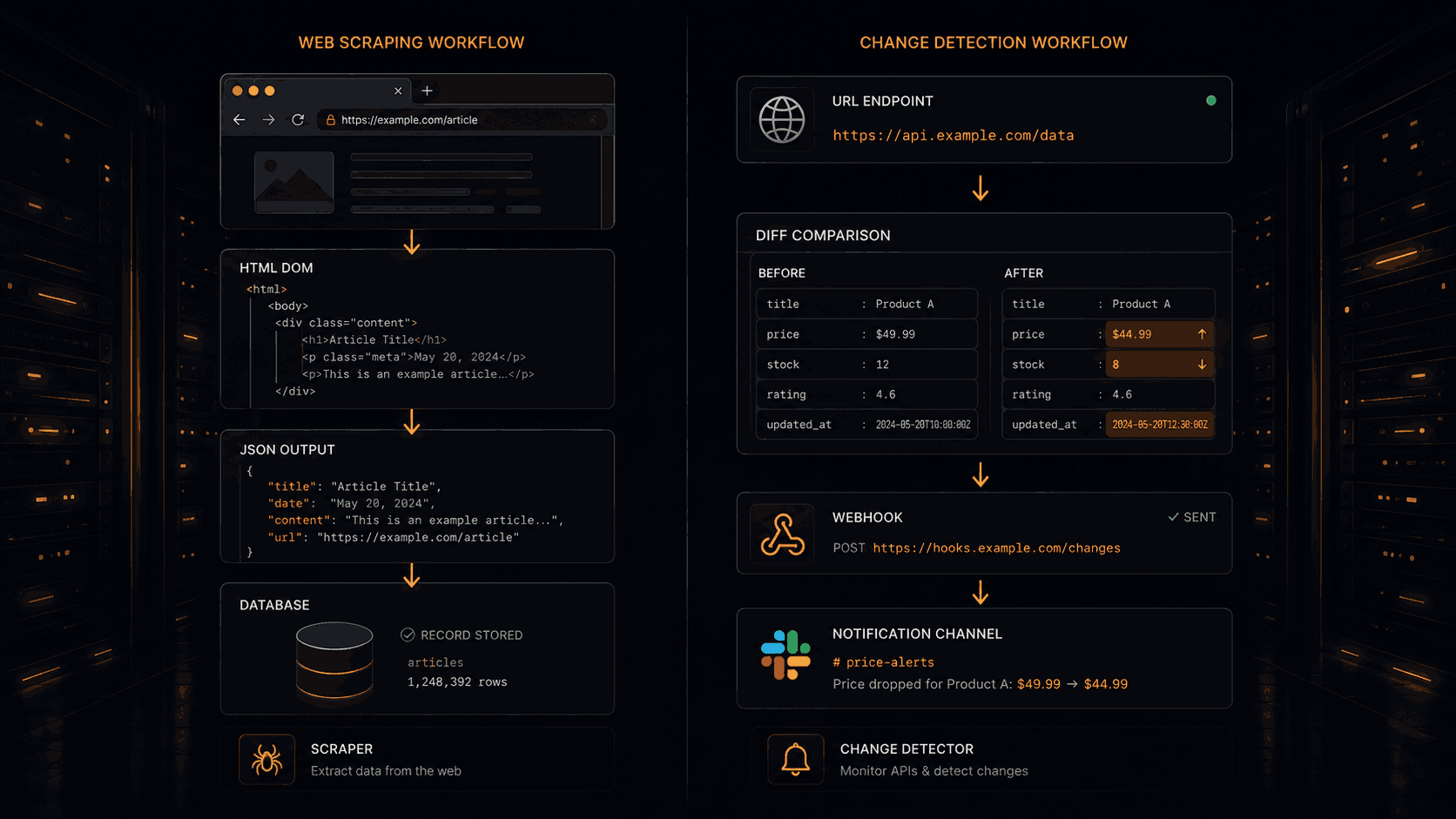
Web scraping is the process of fetching a web page and extracting structured data from it on demand. You point a tool at a URL, it parses the response, and returns fields you asked for. The pipeline typically looks like this:
Fetch → Parse → Extract → Store
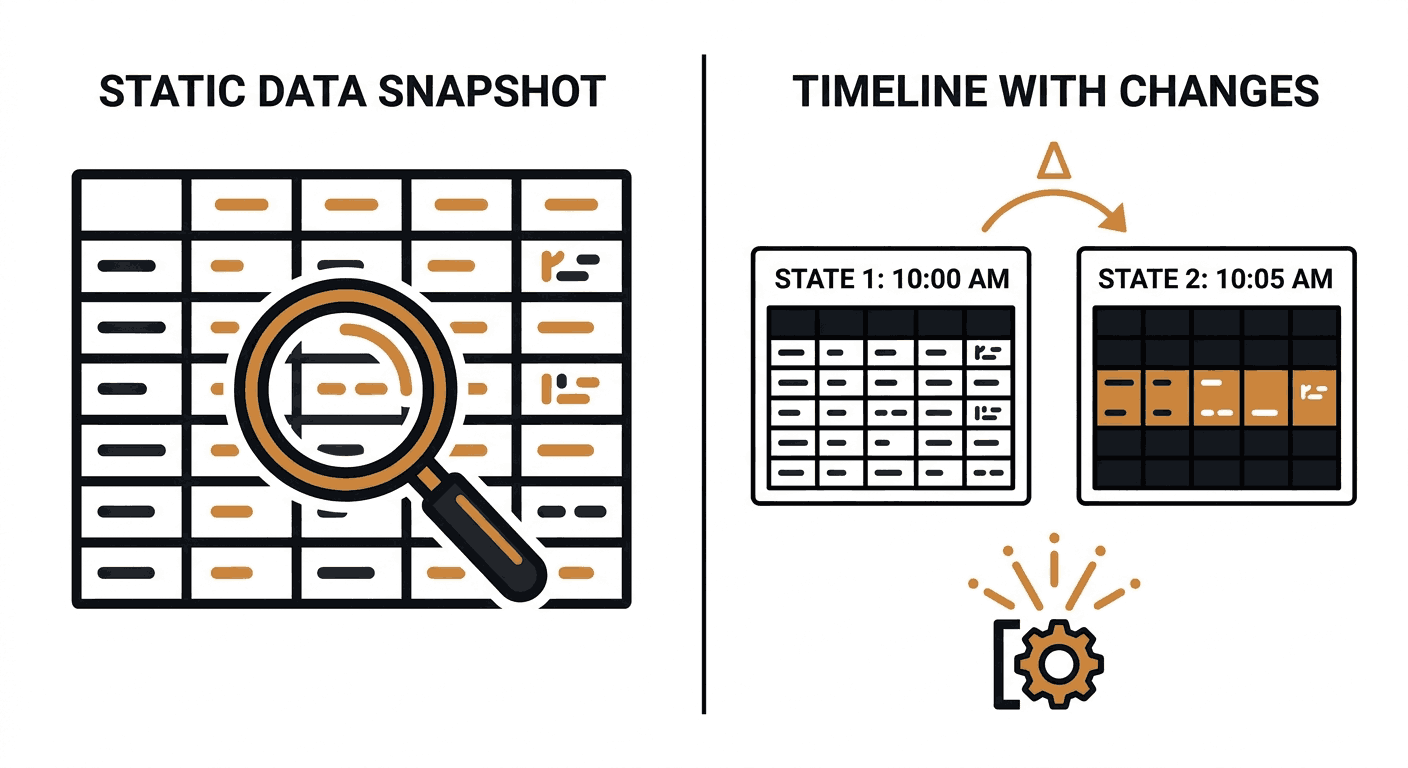
Scraping is stateless by default. It does not know or care what the page looked like last time. You get a snapshot of current data. If you run it again tomorrow, you get another snapshot. Comparing those snapshots is your problem.
Most scraping tools stop at extraction. Platforms like Apify, Zyte, ScrapingBee, and Bright Data are excellent at solving the hard infrastructure problems: proxy rotation, JavaScript rendering, CAPTCHA handling, and anti-bot evasion. They return clean HTML or structured records. What you do with those records afterward is on you.
What Is Web Change Detection?
Web change detection is about tracking the delta between states. You define what you care about, and the system monitors it over time. The output is not "here is the current value" — it is "this field changed from X to Y at this timestamp."
The pipeline looks different:
Fetch → Extract → Compare to previous state → Evaluate predicate → Deliver only on change
That "evaluate predicate" step is what separates real change detection from simple polling. A naive monitor fires every time any byte on the page shifts — an ad rotated, a timestamp updated, a session cookie changed. That is alert noise. Meaningful change detection only fires when a rule you define returns true: price dropped 10%, version field changed, stock status matched a regex.
Key Differences at a Glance
| Dimension | Web Scraping | Web Change Detection |
|---|---|---|
| Primary output | Structured data snapshot | Field-level diff (before / after) |
| Statefulness | Stateless | Stateful — compares to previous run |
| Trigger model | On demand | Time-scheduled, predicate-gated |
| Alert mechanism | You build it | Built in (webhook, Slack, email) |
| Best for | Bulk data extraction | Monitoring specific values over time |
| Noise handling | Not applicable | Predicate-based filtering |
| Infrastructure | Proxies, parsers, storage | Scheduler, diff engine, delivery |
| Typical use case | Dataset collection, ML training, research | Price alerts, release tracking, competitor monitoring |
When Web Scraping Is the Right Choice
Scraping fits best when you need data volume or breadth, not continuous observation.
Bulk data collection. Training a model on product descriptions, building a price index, or extracting contact data from a directory, these are one-time or batch operations where you want as many records as possible.
On-demand lookup. Your application needs to look up a value right now in response to a user action. Scheduled change detection with a 15-minute interval does not help here. You need a synchronous extraction call.
Site crawling. When you need to discover and traverse a large surface area indexing thousands of pages across a domain, scraping infrastructure handles URL queuing, deduplication, and link following in ways that change detection does not.
One-off research. You want a dataset once. You will not monitor it over time. There is no delta to track.
When Web Change Detection Is Better
Change detection wins when the question is "did this specific thing change?" rather than "give me this data."
Competitor pricing. You do not want to store every price tick. You want to know when a competitor drops below your threshold, so you can trigger a repricing workflow.
Dependency tracking. Watching GitHub releases, npm packages, or PyPI versions for changes is a natural change detection problem. You care about the moment the version field changes, not about polling and comparing records yourself.
Regulatory or compliance monitoring. Government portals and regulatory filings change infrequently but critically. A full-page hash monitor fires when anything on the page shifts, no selector required.
Inventory restocks. You need a webhook the moment availability flips from "Out of Stock" to "In Stock." Scraping a page every 5 minutes and storing every result is wasteful. A change detection rule on the availability field fires exactly once, when the condition is met.
SERP and content monitoring. Tracking featured snippets, AI Overview appearances, or keyword rank changes over time is inherently stateful work; it requires history and diffs.
The Hidden Cost of Doing It Yourself
The DIY change detection path is not just hard, it is underestimated.
To build it from scratch you need: a scheduler, a fetch layer (with fallback to headless browser and proxy for JS-heavy or bot-protected sites), a state store, a diff engine that operates at the field level, a predicate evaluator, a delivery system with retries and dead-letter handling, and monitoring for all of the above.
That is roughly the stack most teams take 4-6 weeks to build, and then maintain indefinitely. When the target site changes a class name or moves a JSON key, the fragile selector breaks silently. You find out when someone asks why the alert stopped firing.
Can They Work Together?
Yes, and this is an underused pattern.
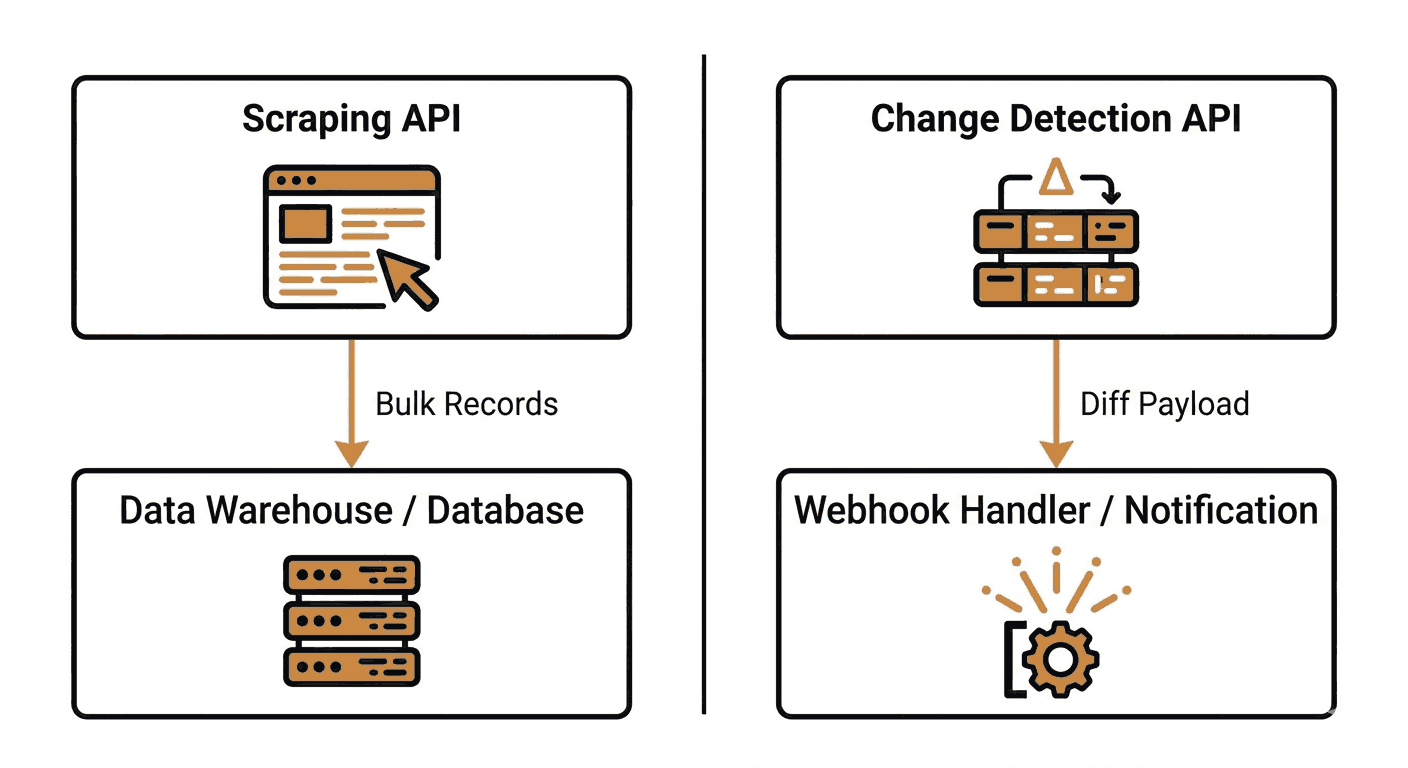
Scraping and change detection solve adjacent problems. A reasonable architecture is:
- Use a scraping API (Zyte, ScrapingBee, Apify) to handle bulk historical data collection, one-off datasets, or synchronous lookups in your application.
- Use a change detection API (Verid.dev) to monitor specific fields on an ongoing schedule and push webhook notifications when meaningful state transitions occur.
The two do not compete. Scraping answers "what is the current state of this data across 10,000 URLs right now." Change detection answers "tell me the moment this one field crosses a threshold I care about."
Real Developer Examples
Tracking npm package releases
You maintain several internal services that depend on upstream npm packages. You want a Slack message the moment a new major version drops.
A scraping API returns the current registry record on demand. But you would need to call it on a schedule, store the previous version, compare on every run, and build Slack delivery yourself. That is the whole loop you are writing.
With Verid.dev, one POST request creates a monitor that closes the loop:
curl -X POST https://api.verid.dev/v1/monitors \
-H "Authorization: Bearer $VERID_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"name": "TypeScript npm release",
"url": "https://registry.npmjs.org/typescript/latest",
"schedule_interval_seconds": 1800,
"extract_config": {
"method": "json_path",
"fields": { "version": "$.version" }
},
"diff_predicate": { "type": "field_changes", "field": "version" },
"deliveries": [{ "type": "slack", "url": "https://hooks.slack.com/your-hook" }]
}'
When the version field changes, Verid fires a Slack message with the before and after values. Nothing else fires.
Competitor price drop alert
You run an e-commerce store and want to know when a competitor drops their price by more than 8%.
curl -X POST https://api.verid.dev/v1/monitors \
-H "Authorization: Bearer $VERID_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"name": "Competitor price watch",
"url": "https://competitor.com/product/widget",
"schedule_interval_seconds": 900,
"extract_config": {
"method": "css",
"fields": { "price": ".product-price" }
},
"diff_predicate": {
"type": "field_decreases_by_percent",
"field": "price",
"threshold": 8
},
"deliveries": [{ "type": "webhook", "url": "https://your-app.com/hooks/pricing" }]
}'
Verid auto-escalates through static fetch, headless browser, and residential proxy if the page requires JavaScript or fights bot detection. You do not configure that — it happens automatically based on what the page needs.
Common Mistakes
Treating every monitoring problem as a scraping problem. If you are scheduling a scraper to run every 5 minutes and writing a custom diff against the previous result, you have already rebuilt half a change detection system. Reach for a purpose-built tool.
Using screenshot-based monitors. Tools that diff screenshots fire on ad rotations, cookie banners, timestamp changes, and layout shifts. These are false positives. If you act on changes to a specific value, you need field-level extraction, not pixel diffs.
Scraping when you only need one field. Fetching an entire product page to check a single price is wasteful. A targeted CSS or JSONPath extractor on a scheduled monitor returns exactly one value per run.
Ignoring first-run behavior. Change detection tools, including Verid.dev, establish a baseline on the first run and do not fire. This is correct behavior. If you expect an immediate alert on setup, you will wait indefinitely for a change that already happened before monitoring started.
Forgetting webhook verification. When a predicate fires and Verid delivers a webhook, verify the HMAC signature before acting on the payload. Unverified webhooks are a surface for spoofing.
Why Developers Use Verid.dev for Change Detection
Verid.dev is a developer-first change detection API. The core loop fetch, extract, diff, evaluate predicate, deliver runs as managed infrastructure. You write a JSON config, not a scraping pipeline.
A few things worth knowing:
Six extraction methods. CSS selectors, XPath, JSONPath, regex, full-page hash, and LLM-powered extraction cover most real-world targets. If a selector breaks when the site redesigns, switching to the AI extractor is a config change.
Nine predicate types. field_changes, field_decreases_by_percent, field_matches_regex, field_equals, and composites with AND/OR let you express precise firing conditions. See the full predicate reference.
Three-layer fetching. Static fetch is attempted first. If extraction returns empty fields, the job retries with a headless browser, then escalates to a residential proxy for bot-protected pages. You configure none of this.
HMAC-signed webhooks with retries. Every delivery carries a Verid-Signature header. Six retries with exponential backoff and a dead-letter queue mean you are not silently losing alerts.
Free tier, no credit card. Five monitors with daily checks are free indefinitely. The Starter plan at $19/month adds 50 monitors and hourly checks.
Frequently Asked Questions
What is the difference between web scraping and web change detection?
Web scraping extracts structured data from a page on demand and returns a snapshot. Web change detection monitors a specific field over time and fires an alert only when a predicate you define is true for example, when a price drops by more than 5% or a version field changes. Scraping is stateless; change detection is stateful and event-driven.
Can I use a scraping API for change detection?
Scraping APIs return data but do not maintain state, run on schedules, evaluate diff predicates, or deliver notifications. You would need to build scheduling, storage, comparison logic, and alerting yourself. For ongoing monitoring, a dedicated change detection API handles that entire loop.
What is a diff predicate and why does it matter?
A diff predicate is a rule evaluated against the before-and-after values after each monitor run. It determines whether a delivery fires. Without predicates, monitors fire on any byte-level change ads, timestamps, cookie banners. Predicates let you say "only alert me when the price field drops by 10% or more," eliminating false positives.
Does web change detection work on JavaScript-rendered pages?
Yes, if the tool supports headless browser fallback. Verid.dev automatically escalates from a static fetch to a headless browser when extraction returns empty fields, then to a residential proxy for bot-protected sites. You do not configure the escalation manually.
A monitor built for specific page fields
Watch a price, stock, or version — not the whole page — and get a signed alert. 5 monitors free, no credit card.
Related posts
XPath vs CSS Selector for Web Scraping: When to Use Each
XPath navigates the full DOM tree. CSS selectors are faster and simpler. Here is exactly when to use each for web scraping - with real config examples.
developer toolsPredicate-Based Alerting: Stop Getting Spammed by Your Monitoring Tool
Alert fatigue is a monitoring tool bug. Verid's predicate system fires only when a change meets a condition — price drop, regex match, or threshold crossed.
competitor monitoringMonitor Competitor Pricing Pages with Webhooks (Step-by-Step)
Set up a webhook receiver that fires on real price changes: verified payload, currency parsing, noise filtering, and routing to Slack or a repricing engine.
brand monitoringGoogle Alerts Alternatives: 7 Tools for Monitoring Things Google Alerts Can't
Google Alerts misses changes to specific pages, prices & JS content. 7 Google Alerts alternatives that actually cover those gaps.